HTML 기반 웹페이지 크롤링
12 Dec 2019 | data crawling html ajax
HTML 기반 웹페이지 크롤링
-
원리 : HTML 문서 중 필요한 내용의 위치에 따라 선택적으로 추출
-
필요한 내용 확인 : 개발자도구 > select an element in the page to inspect it을 선택 > 웹페이지에서 원하는 부분 선택하여 HTML 문서의 위치 확인 > findAll을 이용해서 값 추출
-
실습
-
서울시 공공임대주택의 상세 정보 크롤링 (https://www.myhome.go.kr/hws/portal/sch/selectRentalHouseInfoDetail.do?hsmpSn=31052669&suplyTy=05)
-
“준공년도”의 위치
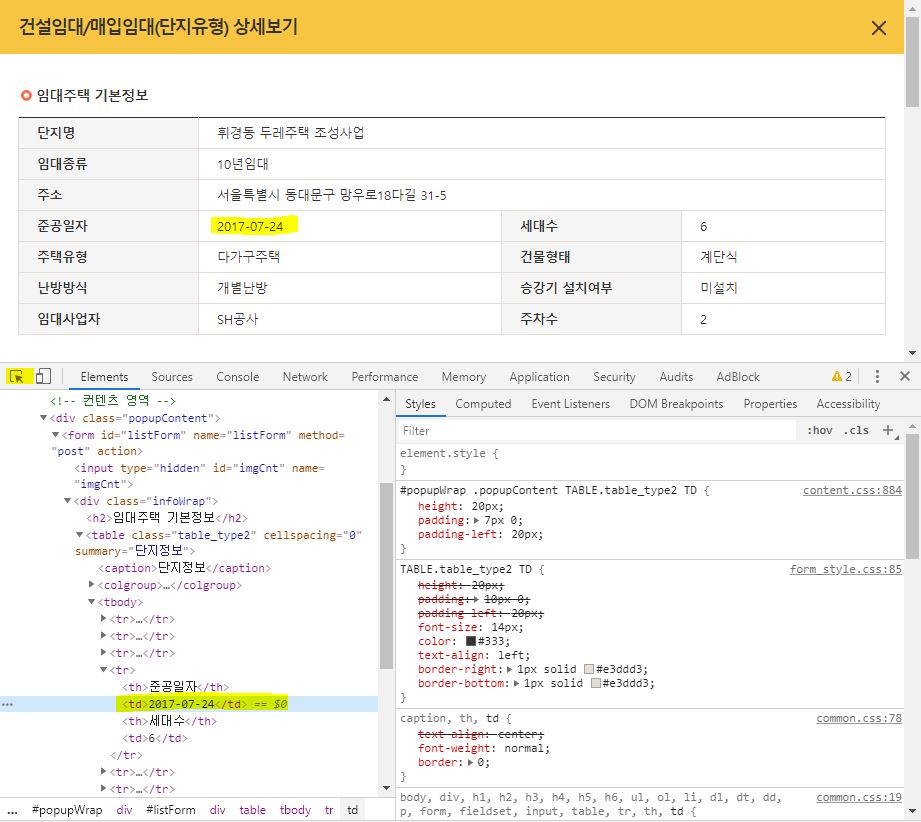
-
필요하다면 strip, replace등을 통해서 불필요한 공백을 제거
-
코드
from urllib.request import urlopen
from bs4 import BeautifulSoup
### 검색 대상 설정
hsmpSn = "30849252" # 각 집별 시리얼 번호
suplyTy = "09" # null 전체, 01 영구임대, 02 국민임대 03 50년임대 04 20년임대 05 10년임대 06 5년임대 07 장기전세 09 행복주택 10 공공기숙사
url = "https://www.myhome.go.kr/hws/portal/sch/selectRentalHouseInfoDetail.do?hsmpSn=" + str(hsmpSn) + "&suplyTy=" + str(suplyTy)
#url = "https://www.myhome.go.kr/hws/portal/sch/selectPubDormInfoDetail.do?hsmpSn=" + str(hsmpSn) + "&suplyTy=" + str(suplyTy) # suplyTy="10"인 공공기숙사의 경우
### 전체 페이지 파싱
pageopen = urlopen(url)
page = BeautifulSoup(pageopen, "html.parser")
### 필요한 데이터 위치에 따라서 추출
year = page.findAll('tr')[3].findAll('td')[0].text
print(year)
### 그러면 "2015-10-06"
HTML 기반 웹페이지 크롤링
-
원리 : HTML 문서 중 필요한 내용의 위치에 따라 선택적으로 추출
-
필요한 내용 확인 : 개발자도구 >
select an element in the page to inspect it을 선택 > 웹페이지에서 원하는 부분 선택하여 HTML 문서의 위치 확인 >findAll을 이용해서 값 추출 -
실습
-
서울시 공공임대주택의 상세 정보 크롤링 (https://www.myhome.go.kr/hws/portal/sch/selectRentalHouseInfoDetail.do?hsmpSn=31052669&suplyTy=05)
-
“준공년도”의 위치
-
필요하다면 strip, replace등을 통해서 불필요한 공백을 제거
-
코드
from urllib.request import urlopen from bs4 import BeautifulSoup ### 검색 대상 설정 hsmpSn = "30849252" # 각 집별 시리얼 번호 suplyTy = "09" # null 전체, 01 영구임대, 02 국민임대 03 50년임대 04 20년임대 05 10년임대 06 5년임대 07 장기전세 09 행복주택 10 공공기숙사 url = "https://www.myhome.go.kr/hws/portal/sch/selectRentalHouseInfoDetail.do?hsmpSn=" + str(hsmpSn) + "&suplyTy=" + str(suplyTy) #url = "https://www.myhome.go.kr/hws/portal/sch/selectPubDormInfoDetail.do?hsmpSn=" + str(hsmpSn) + "&suplyTy=" + str(suplyTy) # suplyTy="10"인 공공기숙사의 경우 ### 전체 페이지 파싱 pageopen = urlopen(url) page = BeautifulSoup(pageopen, "html.parser") ### 필요한 데이터 위치에 따라서 추출 year = page.findAll('tr')[3].findAll('td')[0].text print(year) ### 그러면 "2015-10-06"
-