CSV 파일 형태 파악
07 Jan 2020 | data read_csv csv
CSV 파일 형태 파악
바로 read_csv를 하기에 파일이 너무 무거울 때가 있다.
그런 때는 csv 파일의 형태를 먼저 확인한 후, 필요한 부분만 선택적으로 read_csv 하는게 좋다.
import csv
import pandas as pd
path = r'C:\Users\......\data\\' #위치입력
file = '.....txt' #이름입력
encoder = "CP949"
요약
내용 고민 없이 한 번에 csv shape check하고 싶다면 이렇게!
headsize = 5
lines = []
with open(path+file, encoding=encoder) as f:
col_list = next(csv.reader(f))
fileleng = len(f.readlines())
f.seek(0,2)
filesize = f.tell()
f.seek(0)
for i in range(headsize):
lines.append(f.readline())
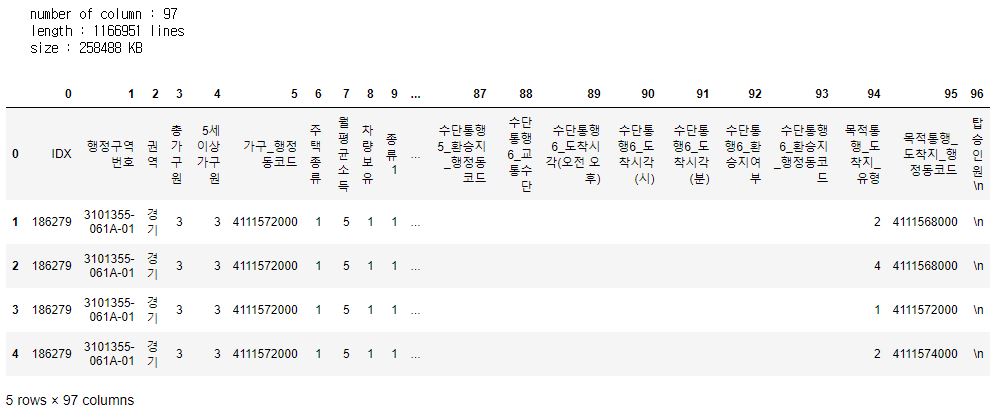
print('number of column : '+ str(len(col_list)))
print('length : ' + str(fileleng) + ' lines')
print('size : ' + str(filesize//1000) + ' KB')
pd.DataFrame([sub.split(",") for sub in lines])
단계별 확인
항목별 확인을 통하여 찬찬히 csv shape check하고 싶다면 이렇게!
csv 파일을 바로 열어서 활용하기 위해서는 입출력 및 접근 함수를 알아야 한다.
또한 csv 파일을 open 할 때, open option에 rb, r 등이 있다. default값은 r이지만, 대부분의 예제는 rb로 나오는데 둘 사이에는 이런 차이가 있다.
# 데이터셋 파일의 크기 확인 1
import os
fsize=os.stat(path+file)
print('size : ' + str(fsize.st_size//1000) +"KB")
# size : 258488KB
# 데이터셋 파일의 크기 확인 2
with open(path+file, encoding=encoder) as f:
f.seek(0,2)
filesize = f.tell()
print('size : ' + str(filesize//1000) + ' KB')
#size : 258488 KB
# 데이터셋의 길이 확인 1
with open(path+file, encoding=encoder) as f:
filelen = len(f.readlines())
print('length : ' + str(filelen) + ' lines')
# length : 1166952 lines
# 데이터셋의 길이 확인 2
with open(path+file, encoding=encoder) as f:
filelen = sum(1 for line in f)
print('length : ' + str(filelen) + ' lines')
# length : 1166952 lines
# header 개수 확인
with open(path+file, encoding=encoder) as f:
col_list = next(csv.reader(f))
print('number of column : '+ str(len(col_list)))
# number of column : 97
# 데이터셋의 header 확인 1
with open(path+file, encoding=encoder) as f:
col_list = next(csv.reader(f))
print('collums :' + str(col_list))
# collums :['IDX', '행정구역번호', '권역', '총가구원', '5세이상가구원', '가구_행정동코드', '주택종류', '월평균소득', '차량보유', '종류1', '연식1', '종류2', '연식2', '종류3', '연식3', '종류4', '연식4', '종류5', '연식5', '종류6', '연식6', '오토바이 50cc미만(대)', '오토바이 50cc이상 100cc미만(대)', '오토바이 100cc이상 260cc미만(대)', '오토바이 260cc이상(대)', '자전거(동력 전기)(대)', '자전거(비동력)(대)', '기 타(종류)', '기 타(대)', '가구주관계', '가구원구분', '출생연도', '성 별', '운전면허증', '정규교육기관', '학교_행정동코드', '직업', '직업기타', '재택근무(집)', '직장_행정동코드', '근무일수', '근무시간', '많은 통행을 하는 일', '통행일자(년)', '통행일자(월)', '통행일자(일)', '통행일자(요일)', '통행유무', '통행안함', '최초출발지_유형', '최초출발지_행정동코드', '목적통행_통행순서', '통행목적', '목적통행_출발시각(오전 오후)', '목적통행_출발시각(시)', '목적통행_출발시각(분)', '목적통행_출발지_유형', '목적통행_출발지_행정동코드', '수단통행1_교통수단', '수단통행1_도착시각(오전 오후)', '수단통행1_도착시각(시)', '수단통행1_도착시각(분)', '수단통행1_환승지여부', '수단통행1_환승지_행정동코드', '수단통행2_교통수단', '수단통행2_도착시각(오전 오후)', '수단통행2_도착시각(시)', '수단통행2_도착시각(분)', '수단통행2_환승지여부', '수단통행2_환승지_행정동코드', '수단통행3_교통수단', '수단통행3_도착시각(오전 오후)', '수단통행3_도착시각(시)', '수단통행3_도착시각(분)', '수단통행3_환승지여부', '수단통행3_환승지_행정동코드', '수단통행4_교통수단', '수단통행4_도착시각(오전 오후)', '수단통행4_도착시각(시)', '수단통행4_도착시각(분)', '수단통행4_환승지여부', '수단통행4_환승지_행정동코드', '수단통행5_교통수단', '수단통행5_도착시각(오전 오후)', '수단통행5_도착시각(시)', '수단통행5_도착시각(분)', '수단통행5_환승지여부', '수단통행5_환승지_행정동코드', '수단통행6_교통수단', '수단통행6_도착시각(오전 오후)', '수단통행6_도착시각(시)', '수단통행6_도착시각(분)', '수단통행6_환승지여부', '수단통행6_환승지_행정동코드', '목적통행_도착지_유형', '목적통행_도착지_행정동코드', '탑승인원']
# 데이터셋의 header 확인 2
with open(path+file, encoding=encoder) as f:
line = f.readline()
print('collums :' + line)
# collums :IDX,행정구역번호,권역,총가구원,5세이상가구원,가구_행정동코드,주택종류,월평균소득,차량보유,종류1,연식1,종류2,연식2,종류3,연식3,종류4,연식4,종류5,연식5,종류6,연식6,오토바이 50cc미만(대),오토바이 50cc이상 100cc미만(대),오토바이 100cc이상 260cc미만(대),오토바이 260cc이상(대),자전거(동력 전기)(대),자전거(비동력)(대),기 타(종류),기 타(대),가구주관계,가구원구분,출생연도,성 별,운전면허증,정규교육기관,학교_행정동코드,직업,직업기타,재택근무(집),직장_행정동코드,근무일수,근무시간,많은 통행을 하는 일,통행일자(년),통행일자(월),통행일자(일),통행일자(요일),통행유무,통행안함,최초출발지_유형,최초출발지_행정동코드,목적통행_통행순서,통행목적,목적통행_출발시각(오전 오후),목적통행_출발시각(시),목적통행_출발시각(분),목적통행_출발지_유형,목적통행_출발지_행정동코드,수단통행1_교통수단,수단통행1_도착시각(오전 오후),수단통행1_도착시각(시),수단통행1_도착시각(분),수단통행1_환승지여부,수단통행1_환승지_행정동코드,수단통행2_교통수단,수단통행2_도착시각(오전 오후),수단통행2_도착시각(시),수단통행2_도착시각(분),수단통행2_환승지여부,수단통행2_환승지_행정동코드,수단통행3_교통수단,수단통행3_도착시각(오전 오후),수단통행3_도착시각(시),수단통행3_도착시각(분),수단통행3_환승지여부,수단통행3_환승지_행정동코드,수단통행4_교통수단,수단통행4_도착시각(오전 오후),수단통행4_도착시각(시),수단통행4_도착시각(분),수단통행4_환승지여부,수단통행4_환승지_행정동코드,수단통행5_교통수단,수단통행5_도착시각(오전 오후),수단통행5_도착시각(시),수단통행5_도착시각(분),수단통행5_환승지여부,수단통행5_환승지_행정동코드,수단통행6_교통수단,수단통행6_도착시각(오전 오후),수단통행6_도착시각(시),수단통행6_도착시각(분),수단통행6_환승지여부,수단통행6_환승지_행정동코드,목적통행_도착지_유형,목적통행_도착지_행정동코드,탑승인원
# 상위 몇 줄 샘플로 확인하기
headsize = 5
lines = []
with open(path+file, encoding=encoder) as f:
for i in range(headsize):
lines.append(f.readline())
pd.DataFrame([sub.split(",") for sub in lines])
# 샘플 몇 줄로 내용 확인하기
import random
samplesize = 5
sample = []
with open(path+file, encoding=encoder) as f:
sample.append(str(f.readline().rstrip())) #column name을 첫 줄로 append
f.seek(0, 2) # 파일 맨 뒤로 이동
filesize = f.tell()
random_set = sorted(random.sample(range(filesize), samplesize))
for i in range(samplesize):
f.seek(random_set[i])
# Skip current line (because we might be in the middle of a line)
f.readline()
# Append the next line to the sample set
sample.append(str(f.readline().rstrip()))
pd.DataFrame([sub.split(",") for sub in sample])
CSV 파일 형태 파악
바로 read_csv를 하기에 파일이 너무 무거울 때가 있다. 그런 때는 csv 파일의 형태를 먼저 확인한 후, 필요한 부분만 선택적으로 read_csv 하는게 좋다.
import csv
import pandas as pd
path = r'C:\Users\......\data\\' #위치입력
file = '.....txt' #이름입력
encoder = "CP949"
요약
내용 고민 없이 한 번에 csv shape check하고 싶다면 이렇게!
headsize = 5
lines = []
with open(path+file, encoding=encoder) as f:
col_list = next(csv.reader(f))
fileleng = len(f.readlines())
f.seek(0,2)
filesize = f.tell()
f.seek(0)
for i in range(headsize):
lines.append(f.readline())
print('number of column : '+ str(len(col_list)))
print('length : ' + str(fileleng) + ' lines')
print('size : ' + str(filesize//1000) + ' KB')
pd.DataFrame([sub.split(",") for sub in lines])
단계별 확인
항목별 확인을 통하여 찬찬히 csv shape check하고 싶다면 이렇게!
csv 파일을 바로 열어서 활용하기 위해서는 입출력 및 접근 함수를 알아야 한다.
또한 csv 파일을 open 할 때, open option에 rb, r 등이 있다. default값은 r이지만, 대부분의 예제는 rb로 나오는데 둘 사이에는 이런 차이가 있다.
# 데이터셋 파일의 크기 확인 1
import os
fsize=os.stat(path+file)
print('size : ' + str(fsize.st_size//1000) +"KB")
# size : 258488KB
# 데이터셋 파일의 크기 확인 2
with open(path+file, encoding=encoder) as f:
f.seek(0,2)
filesize = f.tell()
print('size : ' + str(filesize//1000) + ' KB')
#size : 258488 KB
# 데이터셋의 길이 확인 1
with open(path+file, encoding=encoder) as f:
filelen = len(f.readlines())
print('length : ' + str(filelen) + ' lines')
# length : 1166952 lines
# 데이터셋의 길이 확인 2
with open(path+file, encoding=encoder) as f:
filelen = sum(1 for line in f)
print('length : ' + str(filelen) + ' lines')
# length : 1166952 lines
# header 개수 확인
with open(path+file, encoding=encoder) as f:
col_list = next(csv.reader(f))
print('number of column : '+ str(len(col_list)))
# number of column : 97
# 데이터셋의 header 확인 1
with open(path+file, encoding=encoder) as f:
col_list = next(csv.reader(f))
print('collums :' + str(col_list))
# collums :['IDX', '행정구역번호', '권역', '총가구원', '5세이상가구원', '가구_행정동코드', '주택종류', '월평균소득', '차량보유', '종류1', '연식1', '종류2', '연식2', '종류3', '연식3', '종류4', '연식4', '종류5', '연식5', '종류6', '연식6', '오토바이 50cc미만(대)', '오토바이 50cc이상 100cc미만(대)', '오토바이 100cc이상 260cc미만(대)', '오토바이 260cc이상(대)', '자전거(동력 전기)(대)', '자전거(비동력)(대)', '기 타(종류)', '기 타(대)', '가구주관계', '가구원구분', '출생연도', '성 별', '운전면허증', '정규교육기관', '학교_행정동코드', '직업', '직업기타', '재택근무(집)', '직장_행정동코드', '근무일수', '근무시간', '많은 통행을 하는 일', '통행일자(년)', '통행일자(월)', '통행일자(일)', '통행일자(요일)', '통행유무', '통행안함', '최초출발지_유형', '최초출발지_행정동코드', '목적통행_통행순서', '통행목적', '목적통행_출발시각(오전 오후)', '목적통행_출발시각(시)', '목적통행_출발시각(분)', '목적통행_출발지_유형', '목적통행_출발지_행정동코드', '수단통행1_교통수단', '수단통행1_도착시각(오전 오후)', '수단통행1_도착시각(시)', '수단통행1_도착시각(분)', '수단통행1_환승지여부', '수단통행1_환승지_행정동코드', '수단통행2_교통수단', '수단통행2_도착시각(오전 오후)', '수단통행2_도착시각(시)', '수단통행2_도착시각(분)', '수단통행2_환승지여부', '수단통행2_환승지_행정동코드', '수단통행3_교통수단', '수단통행3_도착시각(오전 오후)', '수단통행3_도착시각(시)', '수단통행3_도착시각(분)', '수단통행3_환승지여부', '수단통행3_환승지_행정동코드', '수단통행4_교통수단', '수단통행4_도착시각(오전 오후)', '수단통행4_도착시각(시)', '수단통행4_도착시각(분)', '수단통행4_환승지여부', '수단통행4_환승지_행정동코드', '수단통행5_교통수단', '수단통행5_도착시각(오전 오후)', '수단통행5_도착시각(시)', '수단통행5_도착시각(분)', '수단통행5_환승지여부', '수단통행5_환승지_행정동코드', '수단통행6_교통수단', '수단통행6_도착시각(오전 오후)', '수단통행6_도착시각(시)', '수단통행6_도착시각(분)', '수단통행6_환승지여부', '수단통행6_환승지_행정동코드', '목적통행_도착지_유형', '목적통행_도착지_행정동코드', '탑승인원']
# 데이터셋의 header 확인 2
with open(path+file, encoding=encoder) as f:
line = f.readline()
print('collums :' + line)
# collums :IDX,행정구역번호,권역,총가구원,5세이상가구원,가구_행정동코드,주택종류,월평균소득,차량보유,종류1,연식1,종류2,연식2,종류3,연식3,종류4,연식4,종류5,연식5,종류6,연식6,오토바이 50cc미만(대),오토바이 50cc이상 100cc미만(대),오토바이 100cc이상 260cc미만(대),오토바이 260cc이상(대),자전거(동력 전기)(대),자전거(비동력)(대),기 타(종류),기 타(대),가구주관계,가구원구분,출생연도,성 별,운전면허증,정규교육기관,학교_행정동코드,직업,직업기타,재택근무(집),직장_행정동코드,근무일수,근무시간,많은 통행을 하는 일,통행일자(년),통행일자(월),통행일자(일),통행일자(요일),통행유무,통행안함,최초출발지_유형,최초출발지_행정동코드,목적통행_통행순서,통행목적,목적통행_출발시각(오전 오후),목적통행_출발시각(시),목적통행_출발시각(분),목적통행_출발지_유형,목적통행_출발지_행정동코드,수단통행1_교통수단,수단통행1_도착시각(오전 오후),수단통행1_도착시각(시),수단통행1_도착시각(분),수단통행1_환승지여부,수단통행1_환승지_행정동코드,수단통행2_교통수단,수단통행2_도착시각(오전 오후),수단통행2_도착시각(시),수단통행2_도착시각(분),수단통행2_환승지여부,수단통행2_환승지_행정동코드,수단통행3_교통수단,수단통행3_도착시각(오전 오후),수단통행3_도착시각(시),수단통행3_도착시각(분),수단통행3_환승지여부,수단통행3_환승지_행정동코드,수단통행4_교통수단,수단통행4_도착시각(오전 오후),수단통행4_도착시각(시),수단통행4_도착시각(분),수단통행4_환승지여부,수단통행4_환승지_행정동코드,수단통행5_교통수단,수단통행5_도착시각(오전 오후),수단통행5_도착시각(시),수단통행5_도착시각(분),수단통행5_환승지여부,수단통행5_환승지_행정동코드,수단통행6_교통수단,수단통행6_도착시각(오전 오후),수단통행6_도착시각(시),수단통행6_도착시각(분),수단통행6_환승지여부,수단통행6_환승지_행정동코드,목적통행_도착지_유형,목적통행_도착지_행정동코드,탑승인원
# 상위 몇 줄 샘플로 확인하기
headsize = 5
lines = []
with open(path+file, encoding=encoder) as f:
for i in range(headsize):
lines.append(f.readline())
pd.DataFrame([sub.split(",") for sub in lines])
# 샘플 몇 줄로 내용 확인하기
import random
samplesize = 5
sample = []
with open(path+file, encoding=encoder) as f:
sample.append(str(f.readline().rstrip())) #column name을 첫 줄로 append
f.seek(0, 2) # 파일 맨 뒤로 이동
filesize = f.tell()
random_set = sorted(random.sample(range(filesize), samplesize))
for i in range(samplesize):
f.seek(random_set[i])
# Skip current line (because we might be in the middle of a line)
f.readline()
# Append the next line to the sample set
sample.append(str(f.readline().rstrip()))
pd.DataFrame([sub.split(",") for sub in sample])