CNN을 convolution의 원리를 중심으로 후려치기
12 Mar 2020 | ML DL CNN
Intro
CNN에 대해 구글링을 하면서 공부하는데 두 가지 어려움이 있었는데,
첫 번째는 전체적인 구조에 대한 설명 없이 세부적인 계산 과정만 나오기 때문이거나,
대부분의 글이 CNN에 속하는 다양한 모델을 구분 없이 혼용하기 때문이었다.
그러니 나는 CNN의 일반적인 구성을 넓은 틀에서부터 정리할테다.
CNN 후려치기!
- CNN(Convolutional Neural Network)
- Image Recognition 등 이미지에서 시각적 패턴을 찾는데 주로 사용되는 인공신경망의 한 종류
- 주어진 이미지가 개인지 고양이인지 구분하려면, 큰 이미지 한 장을 통째로 분석하는 것이 아니라 특징을 더더 강조한 작은 이미지 여러 장으로 만들어서 분석하는 것이 낫다. 그래서 구분하는 과정은 일반적인 인공신경망과 동일하지만, 각각의 특징이 강조된 작은 이미지 여러 장으로 만들어내는 과정이 선행되는 것이 CNN이다. 특징을 강조시키는 필터 행렬과 합성곱(convolution)으로 계산하기 때문에 이름이 CNN인 것이고!
CNN의 다양한 모델
CNN은 convolusion이라는 합성곱 연산 과정을 갖는 인공신경망을 뜻하는 일반적인 용어일 뿐,
세부적인 architecture를 어떻게 짜느냐에 따라서 아주 다양한 모델이 있다.
인기있는 모델에 대한 설명은 여기나 여기를 참고하자!
그냥 “CNN”이라고 구글링하면 매우 다양한 다이어그램이 나와서 혼란스럽기 때문에,
차라리 “LeNet-5”처럼 하나의 모델을 딱 골라서 항상 그 이름으로 구글링 하는 것이 더 쉽다.

CNN의 구성
모델에 따라서 세부적인 형태는 다르지만, CNN은 아래처럼 두 개의 구조로 분리된다.
CNN = (특징을 찾기 위한 feature extraction) + (찾은 특징을 가지고 class를 고르는 fullyconnected layers)

만약 32x32픽셀을 가진 흑백 이미지가 있는데, 이걸 30~100사이의 숫자로 구분한다면,
- input : 0~255 사이의 정수를 가진 32x32의 행렬
- ouput : 30~100 사이의 10단위의 정수
- 접근법 : 일단 random forest등의 classification을 하려면 1x얼마의 행렬로 변환해야 함.
- 방법 1 : 32x32행렬을 순서대로 1x32 + 1x32 + 1x32 + … + 1x32, 즉 1x1024행렬로 전환
전에 해봤던 것처럼 간단하고 정형화된 이미지라면 이정도만 해도 정확도가 제법 높다!
하지만 이런 방법은 행렬내 각각의 값이 이미지의 중요한 특성을 반영하지 못하기 때문에,
이미지가 복잡하다면 정확도가 매우 낮아질 것이다.
- 방법 2 : 이미지의 중요한 특성들을 추출하여 1x얼마의 행렬로 변환
이것이 CNN의 접근법이고, 그래서 feature extracion 과정이 매우 중요하다!
feature extraction의 과정
feature extraction은 convolution + subsampling 을 반복하여, 하나의 넓은 이미지를 특징만 강조된 작은 이미지 여러 개로 변환해주는 과정이다.
- convolution : 어떤 특징을 강조해줄 수 있는 작은 크기의 필터들을 이용해서 이미지의 각 부분씩 찬찬히 뜯어보는 작업
- subsmpling (=pooling) : 이미지의 크기를 줄여서 더 중요한 특징만을 유지하는 작업
따라서, feature extraction은 작은 크기의 필터로 이미지를 조금씩 뜯어보고, 그 중에서도 중요한 특징만 남기는 과정을 반복하는 것이라고 볼 수 있다.
자세한 내용을 알아본다면,
-
convolution의 원리
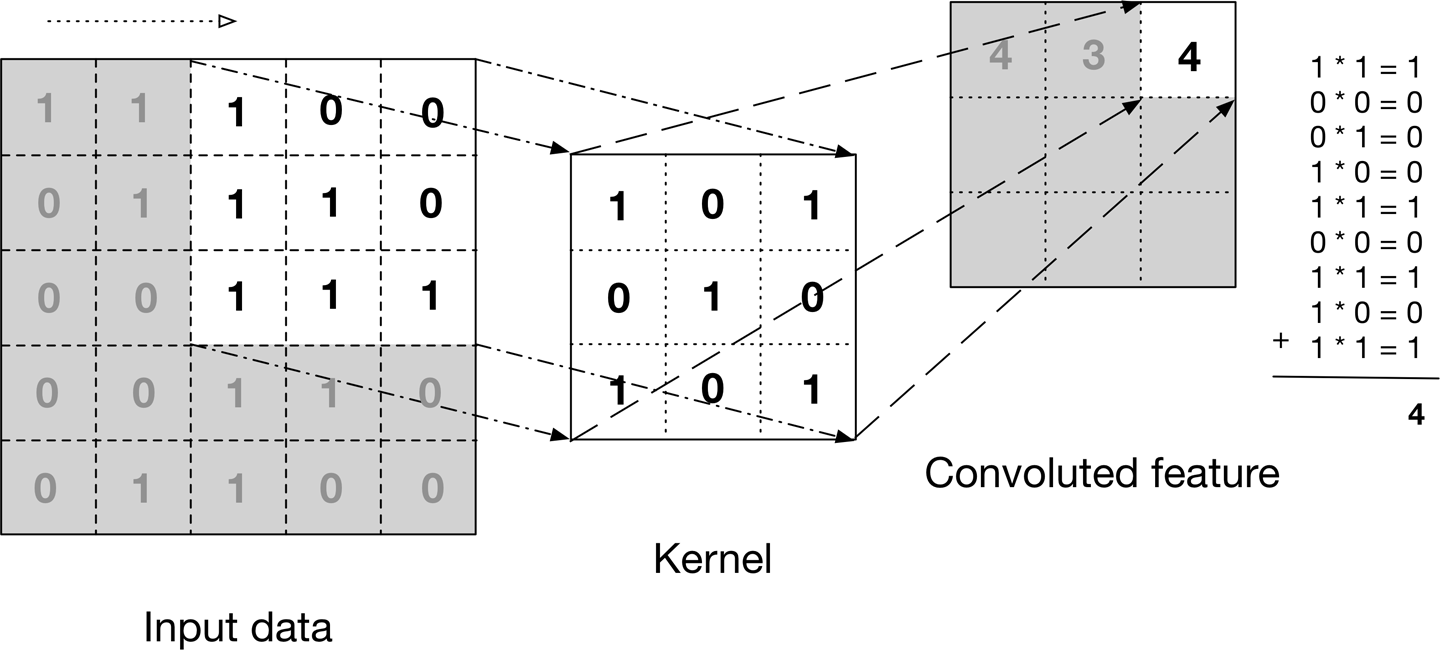
이미지를 각각의 픽셀에 해당되는 값을 가진 행렬로 생각해야 한다.
한 픽셀씩 돌아가면서 필터 행렬과 합성곱(convolution)을 하여 수정된 픽셀의 값을 가진 새로운 행렬들(feature maps = activation maps)을 만들어낸다.
어떤 필터를 몇 개 쓸 것인가에 따라서 만들어지는 행렬의 개수(depth)도 달라진다.

-
- filter (=kernel=mask)
- 원본 이미지를 한 픽셀씩 뜯어볼 때 어떤 특징을 강조해서 볼 것인가를 결정짓는 3x3 혹은 5x5의 행렬!
한번의 convolution을 마친 후 feature map의 개수는 몇 개의 filter를 쓰는가에 따라서 결정된다.
아래처럼 필터 행렬의 값에 따라서 이미지에서 강조되는 특성이 달라진다.

- 필터와의 합성곱 과정에서도 다양한 설정이 가능하다.
- stride : 보폭, 한 픽셀씩 합성곱을 할지 아님 한 픽셀 건너 한 픽셀씩 합성곱을 할지
- padding : 모서리 픽셀 주변을 0으로 채워줄지, 이에 따라 원본 이미지 대비 feature map 크기(width*height)가 작아질지가 결정된다.
-
Subsampling의 원리
각 필터와 합성곱을 마친 feature map의 픽셀의 수를 줄여준다.
그렇다보니 feautre map의 개수(depth)에는 영향이 없고, 크기(width x height)만 줄어들고, 그 과정에서 특징이 더 도드라진다.
일반적으로 max pooling이나 average pooling을 주로 쓴다고 한다.

Classification의 과정은
은 일반적은 ANN에서의 classification과 동일하다. 그러니 스킵!
Intro
CNN에 대해 구글링을 하면서 공부하는데 두 가지 어려움이 있었는데,
첫 번째는 전체적인 구조에 대한 설명 없이 세부적인 계산 과정만 나오기 때문이거나,
대부분의 글이 CNN에 속하는 다양한 모델을 구분 없이 혼용하기 때문이었다.
그러니 나는 CNN의 일반적인 구성을 넓은 틀에서부터 정리할테다.
CNN 후려치기!
- CNN(Convolutional Neural Network)
- Image Recognition 등 이미지에서 시각적 패턴을 찾는데 주로 사용되는 인공신경망의 한 종류
- 주어진 이미지가 개인지 고양이인지 구분하려면, 큰 이미지 한 장을 통째로 분석하는 것이 아니라 특징을 더더 강조한 작은 이미지 여러 장으로 만들어서 분석하는 것이 낫다. 그래서 구분하는 과정은 일반적인 인공신경망과 동일하지만, 각각의 특징이 강조된 작은 이미지 여러 장으로 만들어내는 과정이 선행되는 것이 CNN이다. 특징을 강조시키는 필터 행렬과 합성곱(convolution)으로 계산하기 때문에 이름이 CNN인 것이고!
CNN의 다양한 모델
CNN은 convolusion이라는 합성곱 연산 과정을 갖는 인공신경망을 뜻하는 일반적인 용어일 뿐,
세부적인 architecture를 어떻게 짜느냐에 따라서 아주 다양한 모델이 있다.
인기있는 모델에 대한 설명은 여기나 여기를 참고하자!
그냥 “CNN”이라고 구글링하면 매우 다양한 다이어그램이 나와서 혼란스럽기 때문에,
차라리 “LeNet-5”처럼 하나의 모델을 딱 골라서 항상 그 이름으로 구글링 하는 것이 더 쉽다.
CNN의 구성
모델에 따라서 세부적인 형태는 다르지만, CNN은 아래처럼 두 개의 구조로 분리된다.
CNN = (특징을 찾기 위한 feature extraction) + (찾은 특징을 가지고 class를 고르는 fullyconnected layers)
만약 32x32픽셀을 가진 흑백 이미지가 있는데, 이걸 30~100사이의 숫자로 구분한다면,
- input : 0~255 사이의 정수를 가진 32x32의 행렬
- ouput : 30~100 사이의 10단위의 정수
- 접근법 : 일단 random forest등의 classification을 하려면 1x얼마의 행렬로 변환해야 함.
- 방법 1 : 32x32행렬을 순서대로 1x32 + 1x32 + 1x32 + … + 1x32, 즉 1x1024행렬로 전환
전에 해봤던 것처럼 간단하고 정형화된 이미지라면 이정도만 해도 정확도가 제법 높다!
하지만 이런 방법은 행렬내 각각의 값이 이미지의 중요한 특성을 반영하지 못하기 때문에,
이미지가 복잡하다면 정확도가 매우 낮아질 것이다. - 방법 2 : 이미지의 중요한 특성들을 추출하여 1x얼마의 행렬로 변환
이것이 CNN의 접근법이고, 그래서 feature extracion 과정이 매우 중요하다!
feature extraction의 과정
feature extraction은 convolution + subsampling 을 반복하여, 하나의 넓은 이미지를 특징만 강조된 작은 이미지 여러 개로 변환해주는 과정이다.
- convolution : 어떤 특징을 강조해줄 수 있는 작은 크기의 필터들을 이용해서 이미지의 각 부분씩 찬찬히 뜯어보는 작업
- subsmpling (=pooling) : 이미지의 크기를 줄여서 더 중요한 특징만을 유지하는 작업
따라서, feature extraction은 작은 크기의 필터로 이미지를 조금씩 뜯어보고, 그 중에서도 중요한 특징만 남기는 과정을 반복하는 것이라고 볼 수 있다.
자세한 내용을 알아본다면,
-
convolution의 원리 이미지를 각각의 픽셀에 해당되는 값을 가진 행렬로 생각해야 한다. 한 픽셀씩 돌아가면서 필터 행렬과 합성곱(convolution)을 하여 수정된 픽셀의 값을 가진 새로운 행렬들(feature maps = activation maps)을 만들어낸다. 어떤 필터를 몇 개 쓸 것인가에 따라서 만들어지는 행렬의 개수(depth)도 달라진다.
-
- filter (=kernel=mask)
- 원본 이미지를 한 픽셀씩 뜯어볼 때 어떤 특징을 강조해서 볼 것인가를 결정짓는 3x3 혹은 5x5의 행렬!
한번의 convolution을 마친 후 feature map의 개수는 몇 개의 filter를 쓰는가에 따라서 결정된다.
아래처럼 필터 행렬의 값에 따라서 이미지에서 강조되는 특성이 달라진다.
- 필터와의 합성곱 과정에서도 다양한 설정이 가능하다.
- stride : 보폭, 한 픽셀씩 합성곱을 할지 아님 한 픽셀 건너 한 픽셀씩 합성곱을 할지
- padding : 모서리 픽셀 주변을 0으로 채워줄지, 이에 따라 원본 이미지 대비 feature map 크기(width*height)가 작아질지가 결정된다.
-
-
Subsampling의 원리
각 필터와 합성곱을 마친 feature map의 픽셀의 수를 줄여준다.
그렇다보니 feautre map의 개수(depth)에는 영향이 없고, 크기(width x height)만 줄어들고, 그 과정에서 특징이 더 도드라진다.
일반적으로 max pooling이나 average pooling을 주로 쓴다고 한다.
{kind=link}
Classification의 과정은
은 일반적은 ANN에서의 classification과 동일하다. 그러니 스킵!