csv 파일을 엘라스틱으로
27 Jan 2020 | Elastic Elasticsearch Elastic stack ELK stack data DB
전국 도서관 시각화 (csv file > Elastic)
csv파일을 바로 Logstash로 Elasticsearch로 불러들여서, Kibana로 시각화
- 파이프라인 : csv file > Logstash > Elasticsearch > Kibana
- 작업 순서 : csv 파일 전처리 > Elasticsearch index 생성 > Logstash 설정 및 실행 > Kibana 시각화
1. 데이터 다운로드 및 전처리
- 다운로드 : 공공데이터포털 전국도서관표준데이터
- 전처리
- 컬럼별 값의 위치
- int에 따옴표, 쉼표, 공란 제거
- null값
- 전처리 완료 : 파일
2. Elasticsearch & Kibana 실행
- Elasticsearch 실행
- 명령 프롬프트 관리자 권한으로 실행
- 아래와 같이 해당 폴더 찾아가서
bin\elasticsearch.bat 실행
C:\WINDOWS\system32>cd c:\elastic\elasticsearch-7.5.1
C:\elastic\elasticsearch-7.5.1>bin\elasticsearch.bat
- Kibana 실행
- 명령 프롬프트 관리자 권한으로 실행
- 아래와 같이 해당 폴더 찾아가서
bin\kibana.bat실행
C:\WINDOWS\system32>cd c:\elastic\kibana-7.5.1
C:\elastic\kibana-7.5.1>bin\kibana.bat
- 설치 확인 : 크롬 브라우저에
http://localhost:5601 입력
3. Elasticsearch에 Index생성
데이터를 저장하기 전에 elasticsearch에서 index와 document를 생성해야 한다.
방법 1) cURL 명령을 이용하여 cmd 창에서 속성 등록 및 인덱스 추가 (cURL 설치부터 필요, 참고 : https://ilhee.tistory.com/25)
방법 2) kibana의 dev tools 메뉴 사용
- Kibana Dev Tools 실행 : 몽키스패너 아이콘
- Console에 아래 내용 입력 후
> 아이콘으로 send request
PUT public_library
{
"mappings" : {
"properties" : {
"도서관명" : {"type" : "text", "index" : false },
"시도명" : {"type" : "text", "index" : false },
"시군구명" : {"type" : "text", "index" : false },
"도서관유형" : {"type" : "text", "index" : false },
"휴관일" : {"type" : "text", "index" : false },
"열람좌석수" : {"type" : "integer" },
"자료수(도서)" : {"type" : "integer"},
"소재지도로명주소" : {"type" : "text", "index" : false },
"운영기관명" : {"type" : "text", "index" : false },
"도서관전화번호" : {"type" : "text", "index" : false },
"홈페이지주소" : {"type" : "text", "index" : false },
"library_geo" : { "type" : "geo_point" },
"데이터기준일자" : {"type" : "date" }
}
}
}
- 우측 결과창 확인
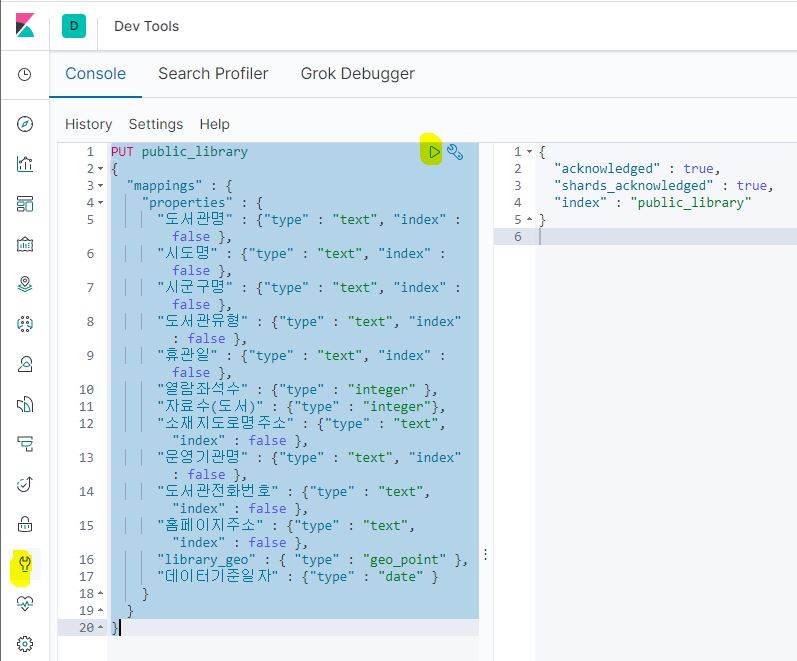
- index health가 yellow인 것이 걱정스럽다면 이 글을 참고
4. Logstash conf 파일 생성 및 실행
- text파일로 config file 생성
- 파일 이름 :
Public_Library.conf
- 내용 : csv파일에서 데이터 입력 후 elasticssearch로 데이터 출력, filter로 일부 포맷 변경 및 삭제
input {
file {
path => "C:/elastic/data/public_library.csv"
start_position => "beginning"
sincedb_path => "/dev/null"
}
}
filter {
csv {
separator => ","
columns => ["도서관명","시도명","시군구명","도서관유형","휴관일","운영시작시각","운영종료시각","열람좌석수","자료수(도서)","자료수(연속간행물)","자료수(비도서)","대출가능권수","대출가능일수","소재지도로명주소","운영기관명","도서관전화번호","부지면적","건물면적","홈페이지주소","latitude","longitude","데이터기준일자"]
}
mutate {
convert => { "latitude" => "float" }
convert => { "longitude" => "float" }
}
mutate {
rename => {
"latitude" => "[library_geo][lat]"
"longitude" => "[library_geo][lon]"
}
}
mutate {
remove_field => ["운영시작시각","운영종료시각", "자료수(연속간행물)", "자료수(비도서)", "대출가능권수", "대출가능일수", "부지면적","건물면적"]
}
}
output {
elasticsearch {
hosts => "localhost:9200"
index => "public_library"
}
stdout {
codec => rubydebug
}
}
- 저장 위치 : 3의 폴더 아래 config 폴더 (ex.
C:\elastic\logstash-7.5.1\config)
-
명령 프롬프트 관리자 권한으로 실행
- 아래와 같이 해당 폴더 찾아가서 실행
C:\WINDOWS\system32>cd c:\elastic\logstash-7.5.1
C:\elastic\logstash-7.5.1>bin\logstash -f config\public_library.conf
하 근데 왜 자꾸 doc.count 가 0일까……@_@
https://www.bmc.com/blogs/elasticsearch-load-csv-logstash/
—
5. 시각화
- Visualize : Create visualization을 눌러서 시각화 자료를 작성한 후,
>아이콘 눌러서 apply changes
참고자료 :
[1] 임성현님 깃헙 : https://github.com/SunghyunLim/public_data/blob/master/elk_library/korea_library_2016.md
[2] mzzz25님 블로그 : https://m.blog.naver.com/sky930425/221515854405
[3] gt1000님 블로그 : https://gt1000.tistory.com/entry/elasticsearch-에-logstash를-이용해서-csv-파일-읽어-들이기
[4] https://blog.naver.com/xomyjoung/221639085235
전국 도서관 시각화 (csv file > Elastic)
csv파일을 바로 Logstash로 Elasticsearch로 불러들여서, Kibana로 시각화
- 파이프라인 : csv file > Logstash > Elasticsearch > Kibana
- 작업 순서 : csv 파일 전처리 > Elasticsearch index 생성 > Logstash 설정 및 실행 > Kibana 시각화
1. 데이터 다운로드 및 전처리
- 다운로드 : 공공데이터포털 전국도서관표준데이터
- 전처리
- 컬럼별 값의 위치
- int에 따옴표, 쉼표, 공란 제거
- null값
- 전처리 완료 : 파일
2. Elasticsearch & Kibana 실행
- Elasticsearch 실행
- 명령 프롬프트 관리자 권한으로 실행
- 아래와 같이 해당 폴더 찾아가서
bin\elasticsearch.bat실행C:\WINDOWS\system32>cd c:\elastic\elasticsearch-7.5.1 C:\elastic\elasticsearch-7.5.1>bin\elasticsearch.bat
- Kibana 실행
- 명령 프롬프트 관리자 권한으로 실행
- 아래와 같이 해당 폴더 찾아가서
bin\kibana.bat실행C:\WINDOWS\system32>cd c:\elastic\kibana-7.5.1 C:\elastic\kibana-7.5.1>bin\kibana.bat - 설치 확인 : 크롬 브라우저에
http://localhost:5601입력
3. Elasticsearch에 Index생성
데이터를 저장하기 전에 elasticsearch에서 index와 document를 생성해야 한다.
방법 1) cURL 명령을 이용하여 cmd 창에서 속성 등록 및 인덱스 추가 (cURL 설치부터 필요, 참고 : https://ilhee.tistory.com/25)
방법 2) kibana의 dev tools 메뉴 사용
- Kibana Dev Tools 실행 : 몽키스패너 아이콘
- Console에 아래 내용 입력 후
>아이콘으로 send requestPUT public_library { "mappings" : { "properties" : { "도서관명" : {"type" : "text", "index" : false }, "시도명" : {"type" : "text", "index" : false }, "시군구명" : {"type" : "text", "index" : false }, "도서관유형" : {"type" : "text", "index" : false }, "휴관일" : {"type" : "text", "index" : false }, "열람좌석수" : {"type" : "integer" }, "자료수(도서)" : {"type" : "integer"}, "소재지도로명주소" : {"type" : "text", "index" : false }, "운영기관명" : {"type" : "text", "index" : false }, "도서관전화번호" : {"type" : "text", "index" : false }, "홈페이지주소" : {"type" : "text", "index" : false }, "library_geo" : { "type" : "geo_point" }, "데이터기준일자" : {"type" : "date" } } } } - 우측 결과창 확인
- index health가 yellow인 것이 걱정스럽다면 이 글을 참고
4. Logstash conf 파일 생성 및 실행
- text파일로 config file 생성
- 파일 이름 :
Public_Library.conf - 내용 : csv파일에서 데이터 입력 후 elasticssearch로 데이터 출력, filter로 일부 포맷 변경 및 삭제
input { file { path => "C:/elastic/data/public_library.csv" start_position => "beginning" sincedb_path => "/dev/null" } } filter { csv { separator => "," columns => ["도서관명","시도명","시군구명","도서관유형","휴관일","운영시작시각","운영종료시각","열람좌석수","자료수(도서)","자료수(연속간행물)","자료수(비도서)","대출가능권수","대출가능일수","소재지도로명주소","운영기관명","도서관전화번호","부지면적","건물면적","홈페이지주소","latitude","longitude","데이터기준일자"] } mutate { convert => { "latitude" => "float" } convert => { "longitude" => "float" } } mutate { rename => { "latitude" => "[library_geo][lat]" "longitude" => "[library_geo][lon]" } } mutate { remove_field => ["운영시작시각","운영종료시각", "자료수(연속간행물)", "자료수(비도서)", "대출가능권수", "대출가능일수", "부지면적","건물면적"] } } output { elasticsearch { hosts => "localhost:9200" index => "public_library" } stdout { codec => rubydebug } } - 저장 위치 : 3의 폴더 아래 config 폴더 (ex.
C:\elastic\logstash-7.5.1\config)
- 파일 이름 :
-
명령 프롬프트 관리자 권한으로 실행
- 아래와 같이 해당 폴더 찾아가서 실행
C:\WINDOWS\system32>cd c:\elastic\logstash-7.5.1 C:\elastic\logstash-7.5.1>bin\logstash -f config\public_library.conf
하 근데 왜 자꾸 doc.count 가 0일까……@_@ https://www.bmc.com/blogs/elasticsearch-load-csv-logstash/ —
5. 시각화
- Visualize : Create visualization을 눌러서 시각화 자료를 작성한 후,
>아이콘 눌러서 apply changes
참고자료 : [1] 임성현님 깃헙 : https://github.com/SunghyunLim/public_data/blob/master/elk_library/korea_library_2016.md [2] mzzz25님 블로그 : https://m.blog.naver.com/sky930425/221515854405 [3] gt1000님 블로그 : https://gt1000.tistory.com/entry/elasticsearch-에-logstash를-이용해서-csv-파일-읽어-들이기 [4] https://blog.naver.com/xomyjoung/221639085235