엘라스틱 데이터 구조의 용어와 고려사항
13 Feb 2020 | Elastic Elasticsearch Elastic stack ELK stack data DB
ES architecture
-
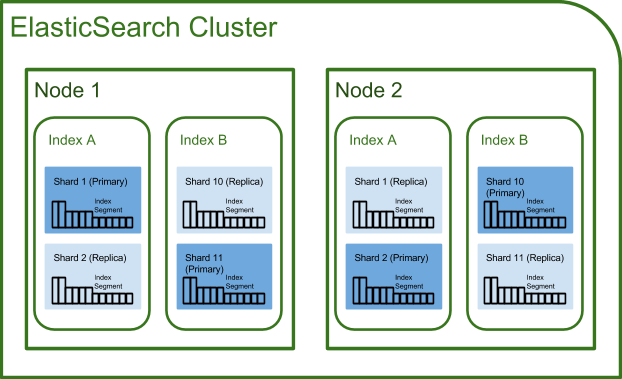
-

Terminology
- Cluster
- 하나 이상의 노드로 이루어진 노드의 집합
- 각각의 클러스터는 데이터의 접근, 교환을 할 수 없는 독립적인 시스템
- 만약에 서비스 확장을 한다면 다른 클러스터를 새로 만들지, 아니면 기존 클러스터 하위에 가져갈지 고민이 필요함
- 한 대의 서버에 여러개의 클러스터가 있을수도, 여러 대의 서버에 한 개의 클러스터가 있을 수도 있음
- Node
- 데이터를 구성하기 위한 물리적 공간
- default : 3개의 node로 구성
- node type
- Data Node : shard의 형태로 데이터를 저장하며, data indexing, searching, and aggregating을 수행
- Master Node : node간 shard 분배, index의 생성과 삭제 등을 수행
- Ingest Node : 중요하게 실시간으로 처리할 node만을 별도로 운영
- Index
- 하나 이상의 shard로 구성 (default는 5개)
- RDB(관계형 데이터베이스)에서 Database에 해당하는 개념. 데이터를 저장할 수 있는 logical namespace
- 유독 Index의 개념이 와닿지 않았다.
- 데이터 소스와 유사한 개념 (index를 추가로 생성할 수 있는 듯 하지만, 기본적으로는 데이터 소스를 추가할 때마다 index가 추가된다. 예를 들어서, import CSV file 하면 한 개의 index가 생성되고, import EXCEL file 하면 다른 index가 추가되고, Metricbeats에서 데이터를 받아오면 또 index가 추가된다.)
- Index 하위의 데이터가 어떤 정보를 어떤 포맷으로 담고 있는지 mapping이 되어 있다. 예를 들어 은행에서 관리하는 고객 정보 index라면, 주소는 string, 현재 잔액은 int 등.
- 하나의 Document를 추가할 때에 어떤 index에 넣을 것인지 지정이 필요하다.
- Shard
- 1개 이상의 Primary shard와 0개 이상의 Replica shard로 구성
- replica : primary shard의 유실 시 복윈을 위한 것이므로, 동일한 node에 배치될 수 없다.
- shard의 개수는 지정할 수 있지만, 그 구성은 알 수 없다.
- Document
- RDBMS에서 table의 한 개 row에 해당하는 개념
- 은행에서 관리하는 고객 데이터라면, 현재 잔고, 신용등급, 보유 통장 등의 정보를 담고 있는 홍길동 씨에 관한 데이터 한 줄
고려사항
- indexing의 필요성 : shard가 크면 효율이 나빠자니 관리가 어렵지 않은 선에서 index를 쪼개는 것이 좋다.
-
cluster의 분리 : 다른 클러스터와는 데이터 접근 및 교환이 불가능하기 때문에, 데이터의 성격이 다르다면 분리하는 것이 좋다.
- 전체 리소스의 크기 : Document가 얼마나 많은가뿐 아니라 index의 개수, shard의 개수를 어떻게 분리하느냐에 따라서도 결정된다. 그래서 데이터 아키텍쳐가 중요한가봐.
ES architecture
Terminology
- Cluster
- 하나 이상의 노드로 이루어진 노드의 집합
- 각각의 클러스터는 데이터의 접근, 교환을 할 수 없는 독립적인 시스템
- 만약에 서비스 확장을 한다면 다른 클러스터를 새로 만들지, 아니면 기존 클러스터 하위에 가져갈지 고민이 필요함
- 한 대의 서버에 여러개의 클러스터가 있을수도, 여러 대의 서버에 한 개의 클러스터가 있을 수도 있음
- Node
- 데이터를 구성하기 위한 물리적 공간
- default : 3개의 node로 구성
- node type
- Data Node : shard의 형태로 데이터를 저장하며, data indexing, searching, and aggregating을 수행
- Master Node : node간 shard 분배, index의 생성과 삭제 등을 수행
- Ingest Node : 중요하게 실시간으로 처리할 node만을 별도로 운영
- Index
- 하나 이상의 shard로 구성 (default는 5개)
- RDB(관계형 데이터베이스)에서 Database에 해당하는 개념. 데이터를 저장할 수 있는 logical namespace
- 유독 Index의 개념이 와닿지 않았다.
- 데이터 소스와 유사한 개념 (index를 추가로 생성할 수 있는 듯 하지만, 기본적으로는 데이터 소스를 추가할 때마다 index가 추가된다. 예를 들어서, import CSV file 하면 한 개의 index가 생성되고, import EXCEL file 하면 다른 index가 추가되고, Metricbeats에서 데이터를 받아오면 또 index가 추가된다.)
- Index 하위의 데이터가 어떤 정보를 어떤 포맷으로 담고 있는지 mapping이 되어 있다. 예를 들어 은행에서 관리하는 고객 정보 index라면, 주소는 string, 현재 잔액은 int 등.
- 하나의 Document를 추가할 때에 어떤 index에 넣을 것인지 지정이 필요하다.
- Shard
- 1개 이상의 Primary shard와 0개 이상의 Replica shard로 구성
- replica : primary shard의 유실 시 복윈을 위한 것이므로, 동일한 node에 배치될 수 없다.
- shard의 개수는 지정할 수 있지만, 그 구성은 알 수 없다.
- Document
- RDBMS에서 table의 한 개 row에 해당하는 개념
- 은행에서 관리하는 고객 데이터라면, 현재 잔고, 신용등급, 보유 통장 등의 정보를 담고 있는 홍길동 씨에 관한 데이터 한 줄
고려사항
- indexing의 필요성 : shard가 크면 효율이 나빠자니 관리가 어렵지 않은 선에서 index를 쪼개는 것이 좋다.
-
cluster의 분리 : 다른 클러스터와는 데이터 접근 및 교환이 불가능하기 때문에, 데이터의 성격이 다르다면 분리하는 것이 좋다.
- 전체 리소스의 크기 : Document가 얼마나 많은가뿐 아니라 index의 개수, shard의 개수를 어떻게 분리하느냐에 따라서도 결정된다. 그래서 데이터 아키텍쳐가 중요한가봐.