R-CNN을 Regional Proposal의 원리를 중심으로 후려치기
13 Mar 2020 | DL CNN R-CNN object detection
이 글을 읽고 object detection에서 풀어야 할 문제가 무엇인지,
R-CNN이 object detection model의 원조급이지만 동시에 두 가지 다른 흐름의 시조라는 흐름을 이해하자.
R-CNN 후려치기
- object detection model 중 two-stage model의 원조
- 뭐가 있을법한 위치를 2000개 골라서(Regional Proposal), 거기에 있는게 무엇인지를 구분하여(CNN) 확률이 높은 것만 추려낸다.
CNN과 R-CNN의 차이
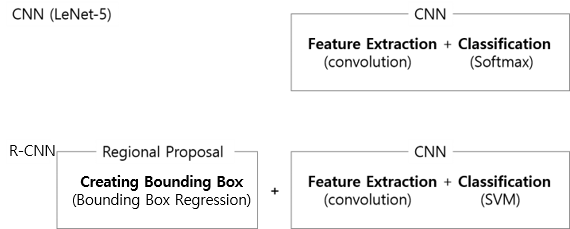
- 큰 차이 : Regional Proposal 모델 추가
- 작은 차이 : CNN에서 classifier로 softmax가 아니라 SVM이라는 상대적으로 단순한 모델을 따로 붙였다는 점. 이게 더 정확도가 높았기 때문이라고.
결국 Regional Proposal의 원리만 이해하면 R-CNN까지도 뽀갤 수 있드아!
Regional Proposal
원리는 단순하다.
Selective search algorithm으로 bounding box의 위치와 크기를 예측한 다음,
Bounding box regression이라는 과정에서 ground truth(training dataset의 정답)와 비교하여
더 나은 bounding box를 만들도록 학습시킨다.
- Selective search algorithm
- bounding box의 위치와 크기를 예측하기 위한 hierachical grouping algorithm
- 대충 비슷한 영역을 묶어놓고, 인근한 영역끼리 유사성이 높으면 점점 묶어나가기
- 유사성의 척도 : Color(픽셀의 값), Texture(주변 픽셀값의 변화량), Size(영역의 크기), FIll(예상되는 영역 크기와의 차이)

- Bounding Box Regression
- bounding box의 x, y, w, h (x좌표, y좌표, 너비, 높이)를 selective search algorithm에서 예측한 값과 ground truth(training dataset의 정답)과 비교하여 그 차이가 작아지도록 학습
난 원리만 후려쳤지만, 논문을 더 자세히 뜯어먹으면서도 명쾌하게 쓴 글이 있다.
미래의 나야, 혹시 까먹거들랑 이 글을 보렴!
이 글을 읽고 object detection에서 풀어야 할 문제가 무엇인지,
R-CNN이 object detection model의 원조급이지만 동시에 두 가지 다른 흐름의 시조라는 흐름을 이해하자.
R-CNN 후려치기
- object detection model 중 two-stage model의 원조
- 뭐가 있을법한 위치를 2000개 골라서(Regional Proposal), 거기에 있는게 무엇인지를 구분하여(CNN) 확률이 높은 것만 추려낸다.
CNN과 R-CNN의 차이
- 큰 차이 : Regional Proposal 모델 추가
- 작은 차이 : CNN에서 classifier로 softmax가 아니라 SVM이라는 상대적으로 단순한 모델을 따로 붙였다는 점. 이게 더 정확도가 높았기 때문이라고.
결국 Regional Proposal의 원리만 이해하면 R-CNN까지도 뽀갤 수 있드아!
Regional Proposal
원리는 단순하다.
Selective search algorithm으로 bounding box의 위치와 크기를 예측한 다음,
Bounding box regression이라는 과정에서 ground truth(training dataset의 정답)와 비교하여
더 나은 bounding box를 만들도록 학습시킨다.
- Selective search algorithm
- bounding box의 위치와 크기를 예측하기 위한 hierachical grouping algorithm
- 대충 비슷한 영역을 묶어놓고, 인근한 영역끼리 유사성이 높으면 점점 묶어나가기
- 유사성의 척도 : Color(픽셀의 값), Texture(주변 픽셀값의 변화량), Size(영역의 크기), FIll(예상되는 영역 크기와의 차이)
- Bounding Box Regression
- bounding box의 x, y, w, h (x좌표, y좌표, 너비, 높이)를 selective search algorithm에서 예측한 값과 ground truth(training dataset의 정답)과 비교하여 그 차이가 작아지도록 학습
난 원리만 후려쳤지만, 논문을 더 자세히 뜯어먹으면서도 명쾌하게 쓴 글이 있다.
미래의 나야, 혹시 까먹거들랑 이 글을 보렴!